
In Azure Synapse Pipelines gibt es zwei häufig verwendete Aktivitäten für die Datenverarbeitung: Copy Data und Data Flow. Beide dienen dem Umgang mit Daten, verfolgen jedoch unterschiedliche Ziele.
| Merkmal | Copy Data | Data Flow |
|---|---|---|
| Hauptzweck | Daten kopieren und verschieben | Daten transformieren |
| Geschwindigkeit | Sehr schnell | Langsamer aufgrund der Verarbeitung |
| Code erforderlich | Nein | Nein (visuelle Oberfläche) |
| Transformationen | Nur einfache Mapping-Funktionen | Umfangreiche Transformationen |
| Spark-Cluster notwendig | Nein | Ja (wird automatisch gestartet) |
| Kosten | Gering | Höher durch Spark-Ressourcen |
| Typische Verwendung | ETL-Laden von Quelle nach Ziel | Bereinigung, Join, Aggregation, Berechnungen |
Copy Data – Daten schnell verschieben
Die Copy Data Activity wird verwendet, um Daten möglichst effizient von einer Quelle zu einem Ziel zu übertragen.
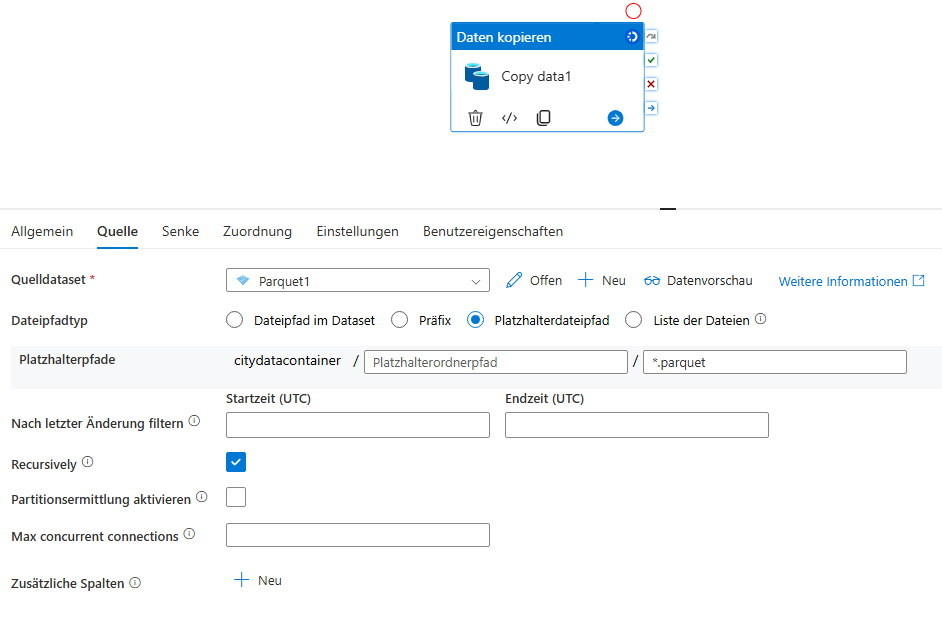
Beispiele:
- SQL Server → Azure Data Lake
- CSV-Datei → Synapse Dedicated SQL Pool
- Oracle → Azure SQL Database
Typische Eigenschaften:
- Hohe Performance
- Unterstützt viele Datenquellen
- Optionales Spaltenmapping
- Keine komplexen Transformationen
Beispiel:
Eine tägliche Kundenliste wird unverändert aus einer SQL-Datenbank in den Data Lake kopiert.
Data Flow – Daten transformieren
Ein Mapping Data Flow ermöglicht umfangreiche Datenverarbeitung ohne Programmierung.
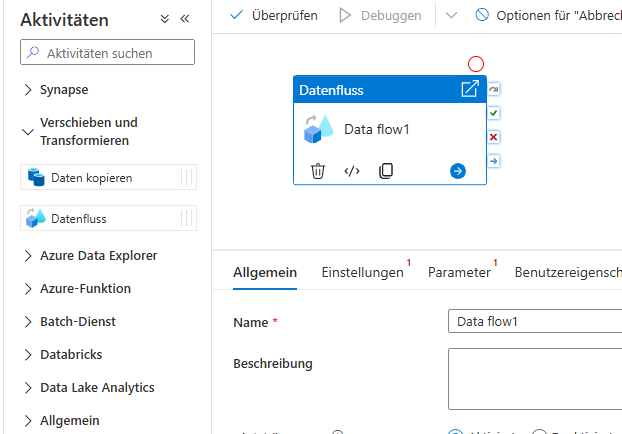
Mögliche Transformationen:
- Filter
- Join mehrerer Tabellen
- Aggregationen
- Berechnete Spalten
- Sortierungen
- Pivot und Unpivot
- Dubletten entfernen
- Slowly Changing Dimensions
Beispiel:
Kundendaten aus mehreren Quellen werden zusammengeführt, Dubletten entfernt und anschließend in ein Data Warehouse geladen.
Wann verwendet man was?
Copy Data verwenden, wenn:
✅ Daten lediglich verschoben werden sollen.
✅ Hohe Geschwindigkeit wichtig ist.
✅ Keine oder nur minimale Transformationen erforderlich sind.
Data Flow verwenden, wenn:
✅ Daten berechnet oder bereinigt werden müssen.
✅ Mehrere Quellen kombiniert werden.
✅ Komplexe ETL-Prozesse benötigt werden.
Typischer ETL-Ablauf
Ein häufiges Muster in Azure Synapse:
- Copy Data
- Daten aus Quellsystemen in den Data Lake laden.
- Data Flow
- Daten transformieren und bereinigen.
- Load
- Ergebnis in das Data Warehouse oder den Dedicated SQL Pool schreiben.
Fazit
Copy Data ist für den reinen Datentransport optimiert und besonders schnell sowie kostengünstig.
Data Flow eignet sich für komplexe Transformationen und ersetzt in vielen Fällen eigene Spark- oder SQL-Skripte.